继续分布式系统的设计图解,下半部分是基础设施,此篇是分布式文件系统。这里面典型就是 GFS,对应开源的版本就是 HDFS。
既然谈到分布式文件系统,我觉得需要从需求层面做一个简单的说明:
- 这里的文件,通常以 “大” 文件为主,越大效率越高,而不会是小文件。小文件的存储,不一定要选择这里说的分布式文件系统——功能上当然行得通,但容易造成效率低下(比如因为元数据占比高,或者是单一 chunk 的空间利用率低),通常它们也可以:
- 存放到某一种 NoSQL 的数据库中去,并辅以其它优化。
- 在这里说的分布式文件系统上面再加一层,在存储上需要做一定的额外优化,比如在 GFS 上实现的 Bigtable(多个小文件可以共享同一个 chunk)。
- 文件的读取功能上支持随机读取,但是主要的模式还是流式读取;修改方面,支持文件随机位置的修改,但主要的模式还是追加写入。无论是流式读取还是追加写入,说白了追求的都是一个微观上的低延迟,从而达到宏观上的高吞吐量。文件的读写可以在同一个块上同时进行。
- 整体看,throughput 优于 latency,优先考虑大规模数据操作的吞吐量,而并非单个文件操作对于低延迟的追求。
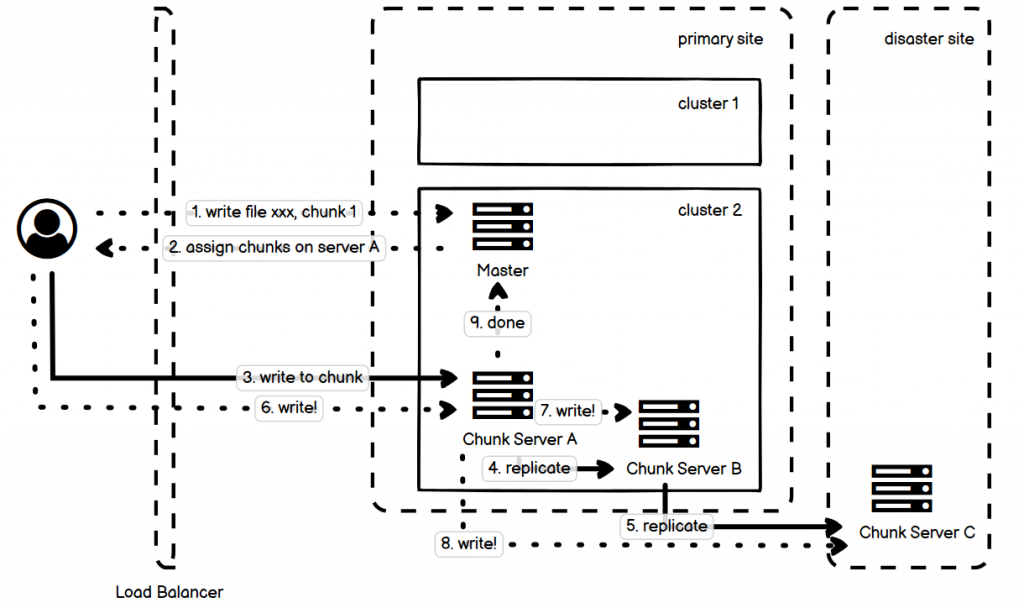
- 图中虚线是控制流,实线是数据流。
- Master 是单一节点,这样整个结构比较简单。Master 上存放了文件的元信息,以及文件内部的偏移量所对应的 Chunk。 Master 利用 snapshot + log 的方式来记录当前状态,备用 Master 可以根据它们迅速接管并还原之前的状态 。
- 整个过程上,Master 最容易成为瓶颈,因此要尽可能地给它减负。比如:
- 读写实际的数据,Client 直接和 Chunk Server 交流;
- 给文件分割存放到不同的 chunk 中,这个分割操作由 Client 直接完成;
- Master 返回 chunk 信息的时候,可以批量返回多个 chunk 信息,而即便是一个 chunk,也可以包含一个 replica 的列表,用于客户端在第一个失败以后可以直接尝试第二个;
- Master 内存中缓存一份完整的文件元信息和 Chunk Server 的路由信息;
- Metadata 要分层,Master 只负责定位到 Chunk Server,而 Chunk Server 上可以进一步存储跟进一步的偏移量等信息(这些信息修改的时候 Master 根本不需要知道);
- Chunk Server 定期主动给 Master 发心跳,而不是由 Master 发起;
- Replica 授权给 Chunk Server 和 Client 配合来完成数据冗余的过程,而不是由 Master 直接管理。
- Chunk 大小是固定的,比如 64M,固定大小便于索引和查询过程中计算位置,无论是校验、冗余还是读写操作,都是以 chunk 为基本单元完成。
- 如果 chunk 的大小太小,就会导致元信息数量过大,加重 Master 的负担,读写操作也要更多次的连接建立等操作,效率降低;
- 如果太大,则意味着 chunk 重传等操作的代价过大,磁盘利用率低,这里面有一个平衡。
- GFS 的元数据对应条目和实际 chunk 大小的比例可达 1/1M,即 64Byte 的元数据条目可以管理 64MB 的 chunk。当然,实际在传输的过程中,并不一定要完成 64M 全部传输才校验一次,在每小块(例如 64KB)传输完毕后就可以做这一小块的校验以提早发现错误。
- 关于小文件单一 chunk 容易引发热点(hot spot)的问题:如果文件只有单一 chunk,那么读取文件的请求落到同一个 chunk 上,就容易把系统冲垮;但是大文件由于分布在多个 chunk 上,读取整个文件需要读取多个 chunk,那么相应地单一 chunk 同一时间承载的压力往往就小。小文件的一种优化方式是增加 replica,从而分散读压力。
- 图中的写入过程分为四步:
- 1、Client 向 Master 提交写文件的某一个 chunk 的请求;
- 2、Master 返回给 Client 具体的 Chunk Server A(primary replica)和 chunk 的位置;
- 3~5、Client 直接和 A 沟通,完成数据上传,而 leader 会同步到 B(secondary replica),接着 B 会同步到 C(secondary replica);
- 6~8、上传完成后,client 发起一个写入命令给 A,A 命令 B 和 C 完成对于刚才上传数据的写入。
- 9、全部节点写入完成,primary replica A 把这一情况汇报给 master。
- 对于写入的过程中,Client 需要写入多个备份,这个备份信息是记录在 Chunk Server 中的。这个过程可以并行写,但是 Chunk Server 之间通信,并根据逻辑时钟来保证写入顺序的准确性,这个顺序由拿到 lease 的主 Chunk Server 来确定。
- 读的过程没有图示表示,但是大致思路还是类似的,Client 从 Master 取得相应的 Chunk Server 的位置,然后 Client 直接从 Chunk Server 去读。
- Chunk 的 checksum 和 chunk 的主数据放在一起,当某一个 Chunk Server 自检发现(自检通常在数据写入的时候进行,也可能定期地体检执行)某一个 chunk 的 checksum 匹配不上,说明数据损坏,它会询问 Master 获得其它数据备份(其它 Chunk Server)的位置,这样它就可以从其它的备份中读取过来写入恢复。
- 备份一般存两份,一份近(primary site),一份远(disaster site)。近的一份保证恢复的过程读取速度很快;远的一份用来保证整个 site 出问题的时候还有数据备份。需要修复的时候询问 Master,它会说备份在哪里。
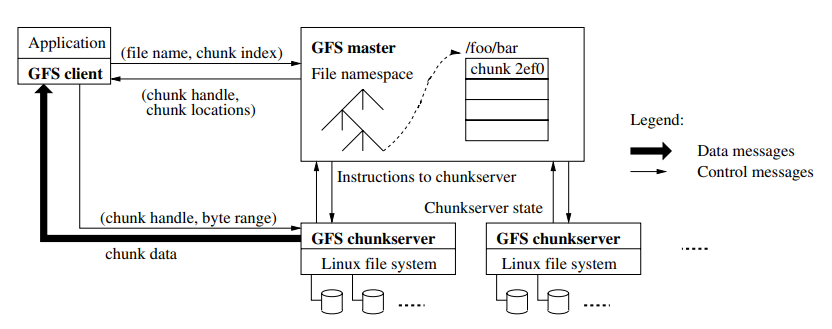
GFS 理论上可以处理随机读、随机写和追加(append)写,但是这两个写的模式里面,随机写非常少,绝大多数都是 append。
Client 去上传文件,控制流和数据流解耦开,并且文件上传和写入存储的步骤也分离开。我在上面的图示里面画的是,client 上传数据给 primary 的 chunk server,其实这个是不一定的,上传给谁要看谁距离 client 更近。
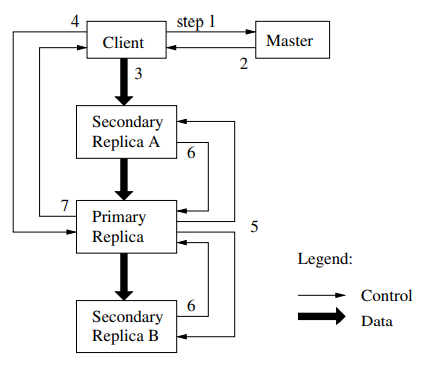
GFS 默认数据存三份,数据在 chunk server 之间同步使用级联的方式。上图所示,Client 先去询问 master chunk server 的位置,有三个 replica,所以 client 上传数据缓存到最近的那个,也就是图中的 A,接着 A 再传给 Primary,Primary 再传给 B。注意这些步骤完成后,数据还并没有实际写入磁盘。接着 Client 给 Primary 一个指令,让写磁盘,于是 Primary 会给手头需要写入的工作进行排序,写入并且通知 A 和 B 也写入,都完成以后告知 Client。
GFS 是单 master 的系统,设计风格和以前见过的 Dynamo 这样的迥然不同。Dynamo 是尽可能去避免中心节点,而 GFS 则是认可这样的中心节点。单 master 的最大好处无疑就是维护一个可视作 source of truth 的全局状态,大大简化整个系统。但是缺点也很明显,比如单节点故障的问题,吞吐量瓶颈的问题等等,为此,GFS 做了一定的优化:
- 尽可能减小 master 需要掌管的信息量。比如说,采用 64M 这样比较大的 chunk size,GFS 本来就是对于大文件和超大文件的存储而优化设计的;比如说,master 只要知道文件的 chunk 在哪个节点上,而把 chunk 具体在节点上的偏移量这件事情全权委托给 chunk server 去管理;再比如,master 的操作日志不会记录数据在哪个 chunk 上这样的信息,而这样的信息它希望在 master 启动的时候 chunk 能主动汇报给它,从而简化 master 的工作逻辑。
- Master 会尽量吧数据缓存在内存中,增加读取速度。
- 为了保证 master 的数据不丢失,采用了操作日志+checkpoint 这样如今看来比较常用的方法。操作日志也是要备份写入以避免 master 挂掉,丢失数据。
- Master 如果挂掉了,GFS 以外的监控系统会启动一个新的 master(说真的,这个设计听起来略有些掉价)。另外,GFS 采用 shadow master,就是说它在正常情况下,会异步同步 master 的状态,对于读操作,它是可以和 master 一起分担压力的,即便是 master 已经失效,它还是可以工作。数据异步同步的关系,shadow master 会略有延迟,但是它会被用来响应读取那些不怎么修改的文件和被允许读到 metadata stale 状态的文件。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》