以下来自 John Hann 的实现,这段代码引起了我的注意,它用巧妙的方法把方法调用的结果缓存起来了。
代码解析:
// memoize: 使用 memoization 来缓存的通用方法
// func: 要被缓存的方法
// context: 方法执行上下文
// Note: 方法必须是外部可访问的,参数是可字符序列化的
function memoize (func, context) {
function memoizeArg (argPos) { //参数表示原始方法中参数的位置
var cache = {}; //这个缓存的 key 是参数,value 是执行结果
return function () { //返回一个函数闭包
if (argPos == 0) { //第一个参数,如果参数在缓存的 key 中不存在,就执行原始函数并且存储执行结果
if (!(arguments[argPos] in cache)) {
cache[arguments[argPos]] = func.apply(context, arguments);
}
return cache[arguments[argPos]];
}
else { //不是第一个参数,如果参数在缓存的 key 中不存在,就递归执行 memoizeArg 方法,原始方法中参数的位置-1
if (!(arguments[argPos] in cache)) {
cache[arguments[argPos]] = memoizeArg(argPos - 1);
}
return cache[arguments[argPos]].apply(this, arguments);
}
}
}
var arity = func.arity || func.length; //func 参数的长度,javascript 中用 length 属性,其它的用 arity 属性
return memoizeArg(arity - 1); //从最后一个参数开始递归
}
使用:
var mem = memoize(func, this); alert(mem.call(this,1,1,2)); alert(mem.call(this,2,1,2)); alert(mem.call(this,3,1,3)); alert(mem.call(this,2,2,4));
看似简单,再一看好像也并不易懂,可是如果能对闭包的使用比较熟悉的话,就很好理解了。经过上面几次 mem.call 的调用之后,形成的是一棵树,每个节点都是一个闭包,每个闭包内有一个 cache,每个 cache 的 key 都是树分支:
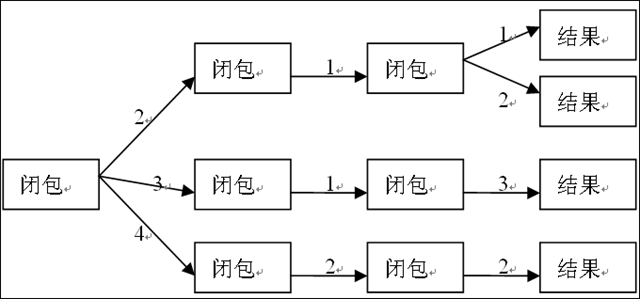{kind=link}

(注:上面图中的 “结果” 也是一个闭包,只不过 argPos 为 0 而已)
不过方法有诸多,比如 limboy 说:
function Memoize(fn){
var cache = {};
return function(){
var key = [];
for( var i=0, l = arguments.length; i < l; i++ )
key.push(arguments[i]);
if( !(key in cache) )
cache[key] = fn.apply(this, arguments);
return cache[key];
};
}
实现更简易,不过把参数 push 到一个数组内,再把数组当 key,而 key 是只支持字符串型的,因此这点在使用上需要注意(比如一个对象 tostring 之后可能只看到”[object Object]” 了),它的功能比上面那个要弱一些。
改进这一点也不难,把参数另立一个对象即可,而原 cache 对象和这个另立的参数对象使用一个 ID 关联起来:
function Memoize(fn){
var cache = {}, args = {};
return function(){
for( var i=0, key = args.length; i < key; i++ ) {
if( equal( args[i], arguments ) )
return cache[i];
}
args[key] = arguments;
cache[key] = fn.apply(this, arguments);
return cache[key];
};
}
还有一些其他的办法,都可以写成简洁的函数式方法。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》