这些笔记是在自己的 Mac Mini 上面折腾了一些记录,主要是安装一些重要的大模型工具,把这些工具连接起来,建立自己的私有本地知识库等等,以备查阅。后续不定时更新。
安装 OrbStack
OrbStack 是专门为 MacOS 设计的快速、轻量级的虚拟化工具,可以作为本地 Docker、K8s 和 Linux VM 的超容易替代品。因为它丢掉了跨平台的包袱,直接在系统内核级别支持虚拟机指令,动态分配内存等等做法,让它变得超快。就以 Docker 为例,它可以把冷启动速度从几十秒优化到一两秒。
我是在 Apple M4 芯片的 Mac mini 上面折腾的,首先要保证我的应用全部都是 M4 芯片直接支持的,而不是通过 Rosetta 2 兼容性转换过来的。在检查 Homebrew 的时候,发现 brew 命令的路径在/usr/local/bin/brew,这就是说 brew 在 Intel CPU 的模拟路径上,因此重新安装了 Homebrew,修改 PATH 以后检测发现 brew 已经在 ARM 的原生路径上了:/opt/homebrew/bin/brew。
这再安装 OrbStack 就行了:
brew install --cask orbstack使用 orb 命令启动的时候,OrbStack 列出了三大核心功能:Docker、K8s 和 Linux VM,基本上足以完成我日常折腾的最核心需要了。
安装以后,docker 的命令就完全支持了,启动一下看看:
docker run -p 80:80 docker/getting-started安装 Cursor
我在公司里代码编辑器使用的是 Intellij 和 Windsurf,后者是真正的 AI 原生 IDE。不过现在打算安装 Cursor,作为 Windsurf 的竞品,它有更优秀的综合体验。
安装 Miniforge
首先要安装 Conda,有很多其他的库管理系统,但因为 Conda 是一个更通用的环境管家,不仅限于 Python,包括 Python 库底层的 C++一并搞定。
Miniforge 把 Conda 工具包装了一下,并且针对 Mac 定制化了一下。Conda 的定制化有很多,Miniforge 是其中之一,开源免费,支持原生 ARM。
安装 Ollama
Ollama 是一个可以在本地电脑上运行 LLM 的工具。然后可以跑 Llama 模型了:
ollama run llama3.2用 Cursor 写一段小程序来调用它:
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class LocalLLMClient {
public static void main(String[] args) {
String endpoint = "http://localhost:11434/api/generate";
String jsonPayload = "{"
+ "\"model\": \"llama3.2\","
+ "\"prompt\": \"Who are you?\","
+ "\"stream\": false"
+ "}";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(endpoint))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(jsonPayload))
.build();
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("HTTP status code: " + response.statusCode());
System.out.println(response.body());
} catch (Exception e) {
e.printStackTrace();
}
}
}运行它,可以得到:
HTTP status code: 200
{"model":"llama3.2","created_at":"2026-03-29T23:54:11.011864Z","response":"I'm an artificial intelligence model known as Llama. Llama stands for \"Large Language Model Meta AI.\"","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,15546,527,499,30,128009,128006,78191,128007,271,40,2846,459,21075,11478,1646,3967,439,445,81101,13,445,81101,13656,369,330,35353,11688,5008,16197,15592,1210],"total_duration":868990167,"load_duration":99794167,"prompt_eval_count":29,"prompt_eval_duration":263381208,"eval_count":23,"eval_duration":497184294}Ollama 这个工具是最核心的部分,其他很多工具都需要连接在 Ollama 上面跑的大模型来完成。
安装 LM Studio
LM Studio 基本上就是本地的大模型图形化工具,和 Ollama 在功能上是有重叠的。一般说来,Ollama 可以用作后台程序运行和工程化调用,但是 LM Studio 适合选型和调试。
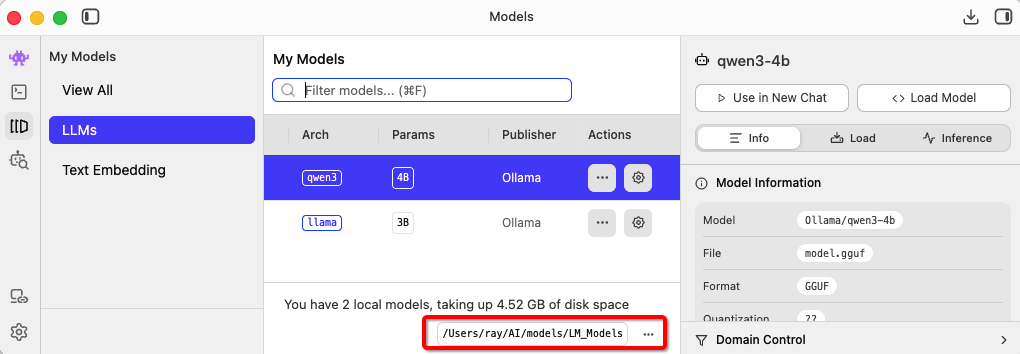
模型文件都比较大,已经使用 Ollama 下载了的,就不需要 LM Studio 再下载一遍了。模型都被下载到了~/.ollama/models/blobs/sha256-xxx,根据文件大小可以找到那个实际的模型文件。
然后创建 gguf 的软链接,比如:ln -s ~/.ollama/models/blobs/sha256-3e4cb14174460404e7a233e531675303b2fbf7749c02f91864fe311ab6344e4f ~/AI/models/LM_Models/Ollama/qwen3-4b/model.gguf,这样在加载以后,这个文件就能够被识别了:
安装 Claude
我们可以配置 /Users/ray/Library/Application Support/Claude 来允许 Ollama 来访问 Claude 的 MCP 接口:
{
"preferences": {
"coworkWebSearchEnabled": true,
"coworkScheduledTasksEnabled": false,
"ccdScheduledTasksEnabled": false
},
"mcpServers": {
"local_ollama": {
"command": "/usr/local/bin/npx",
"args": [
"-y",
"ollama-mcp-server",
"http://localhost:11434"
]
}
}
}再去问 Claude 的时候,它就能访问 Ollama 并得到安装的模型了:
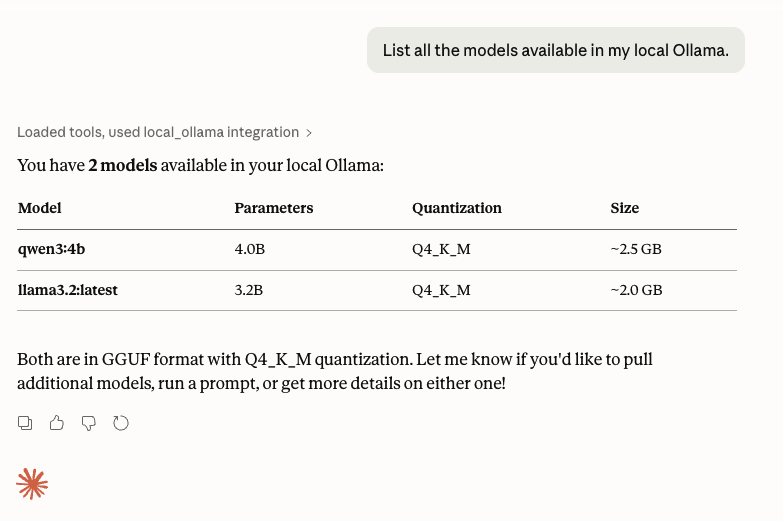
它的这个操作,其实是和本地运行 curl http://localhost:11434/api/tags 或者 ollama list 是一样的。
为了能更方便地使用,最好打开语音操作支持。在 Mac 的设置里面,找到 keyboard,语言列表里面需要把中文英文都勾上:
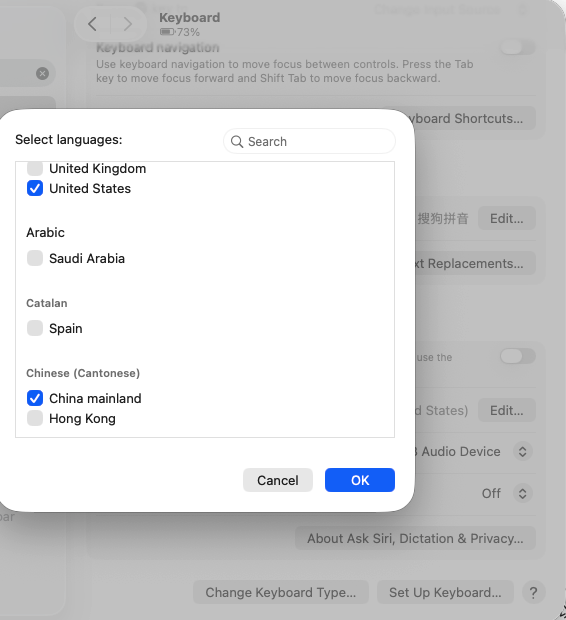
并且还可以设置为双击 Command 按键就可以调出语音输入。
在 general 的语言和地区设置里面,加上中文:

再配置好 Gmail 的 connector,就可以让 Claude 做一些更有意义的工作了。比如,我让它分析最近看的房子,生成一份详细的报告发到家人的邮箱里。
安装 AnythingLLM
下载安装 AnythingLLM,下面使用它来选择本地模型,选择远程网站或者本地文件,并进行本地 RAG(检索增强生成,Retrieval-Augmented Generation),生成属于自己的私有/本地知识库。
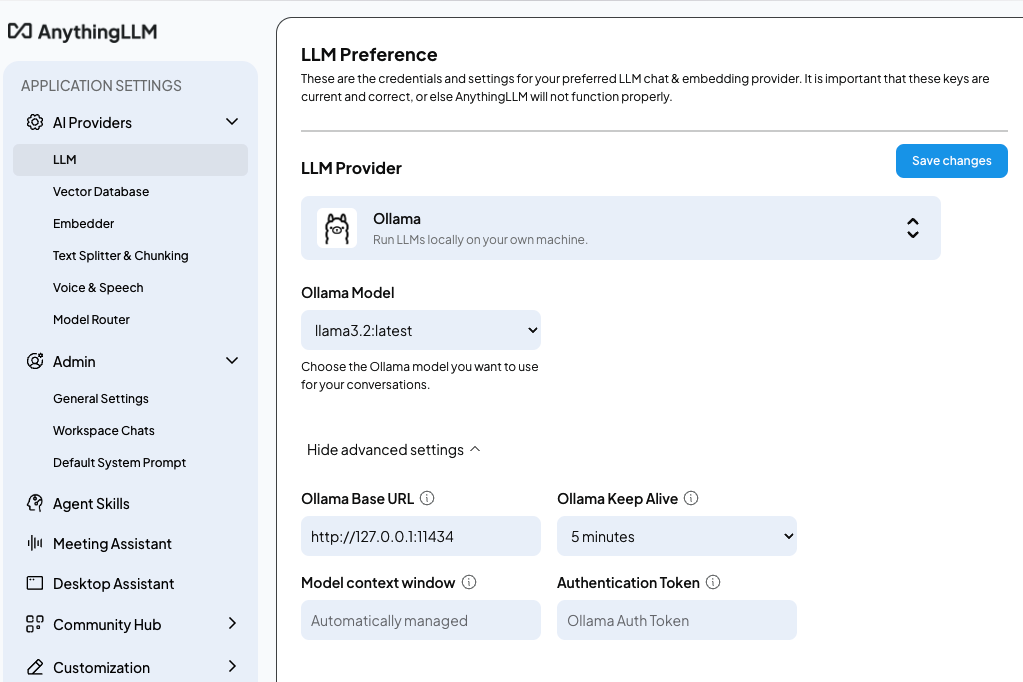
设置里面,先选择推理模型(LLM Preference):
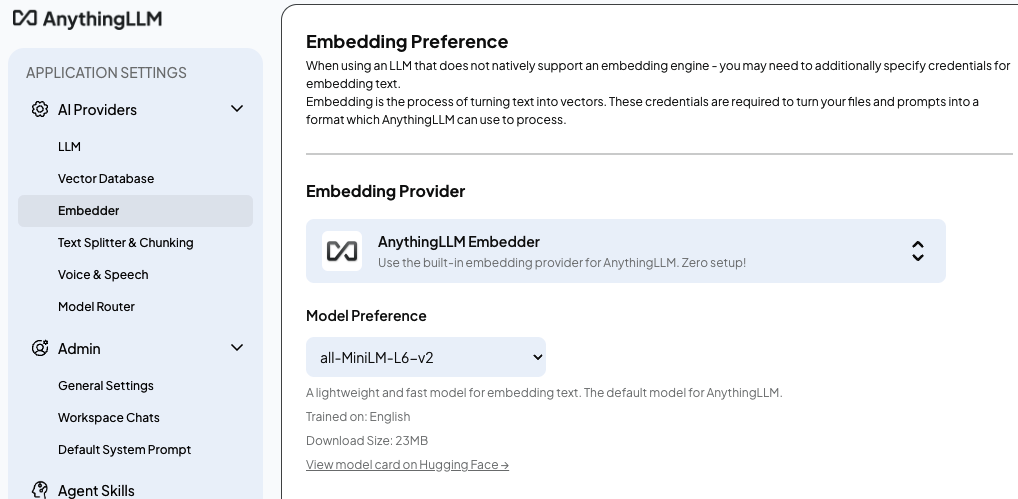
再选择嵌入模型(Embedding Preference):
最后选择向量数据库 (Vector Database),保持默认。
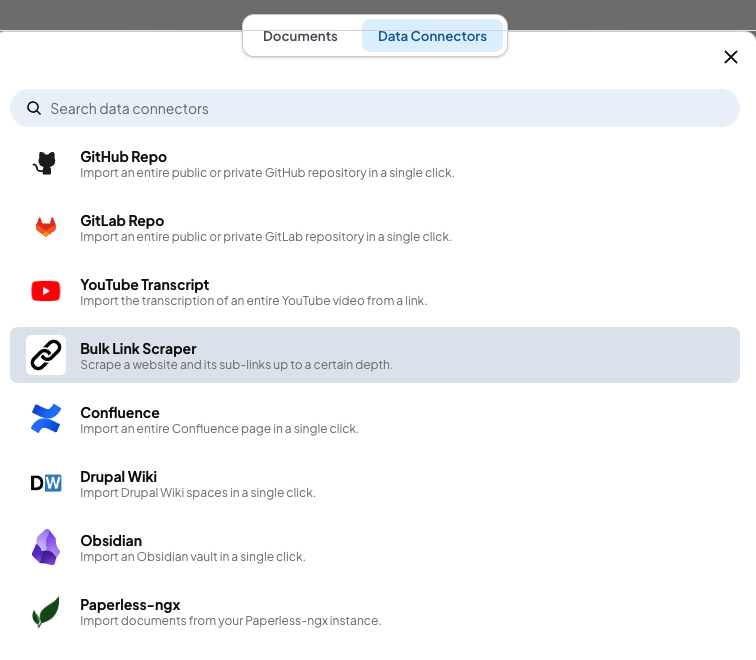
使用 Bulk Link Scraper 这个 Data Connector 可以去扒拉网站上的内容:
运行 tail -f ~/Library/Application\ Support/anythingllm-desktop/storage/logs/collector*.log 可以看到抓取的详细信息。
抓取完成后,回到 Documents 页就可以把抓到的内容加到 Workspace 里面去:Move to Workspace -> Save and Embed。
除了抓取网页,也可以上传一些本地的文件给它。
不过,文件较多的时候,它的可用性就比较差了。我们需要一些其他的工具。
搭建 Dify 环境
为了解决前述问题,下面搭建搭建 Dify + 本地 Ollama 的组合。Dify 是一个 “Agentic Workflow Builder”,它底层集成了非结构化数据解析引擎,可以把各种格式的文件转成文本。
首先修改 Ollama 的环境变量,使其监听所有网卡:
launchctl setenv OLLAMA_HOST "0.0.0.0"这一步需要重启 Ollama。
现在本地有的 qwen3 和 llama3 都是 chat 模型,还需要专属的 Embedding 向量模型:
ollama pull nomic-embed-textDify 官方提供了完整的 Docker 编排文件,包含前端、后端、PostgreSQL 数据库、Redis 缓存以及向量索引组件。
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env再把上面.env 文件的 EXPOSE_NGINX_PORT 这一项端口从 80 改成 8080,以避免冲突。
还需要加上这样的配置以放宽文件上传限制:
UPLOAD_FILE_SIZE_LIMIT=10000
UPLOAD_FILE_BATCH_LIMIT=20000环境配置文件准备好以后,就可以启动所有容器组件了。
docker compose up -d于是乎,pull 了一大堆 image:
启动了一堆 container。以后要启动和停止,以及看日志,使用:
docker compose down
docker compose up -d
docker compose logs -f访问 http://localhost:8080/ 并创建用户。
接着 Settings 里面添加 Ollama 的 plugin,
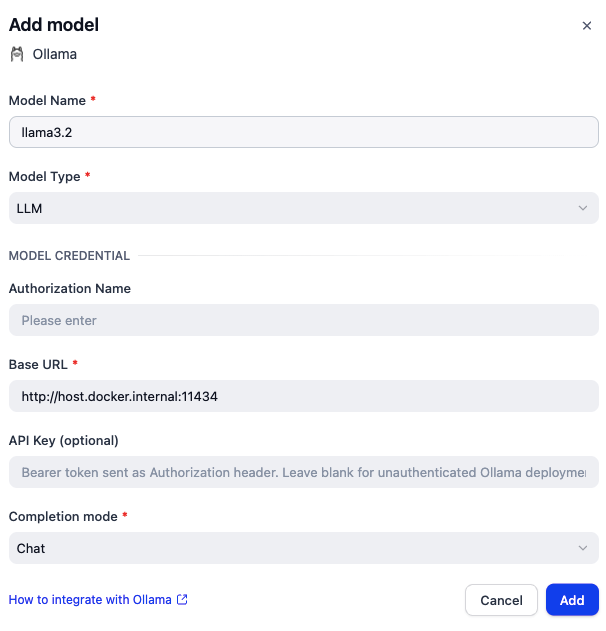
先配置 LLM 的 llama3 模型,再配置 Text Embedded 的 nomic-embed-text 模型。这其中的 Base URL 不能用 localhost,而是要使用 host.docker.internal,因为 Dify 在 Docker 内部运行。
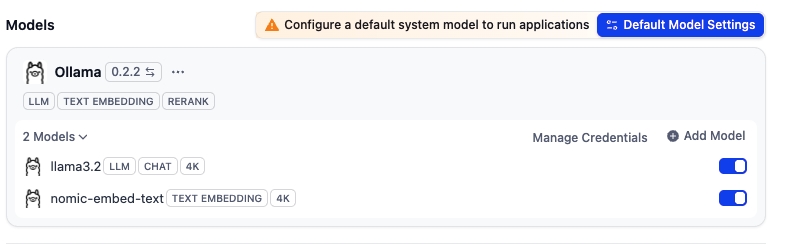
之后,就选中一个知识库,然后分批追加文件。因为软件一次性没法导入一个太大的文件夹,否则页面会卡死,所以这一点需要注意。
之后,还可以把网站等其它形式的数据导进来,这样自己的知识库就会更加全面。如果是爬网站的话,可以去 Firecrawl 注册一个账号,得到一个 API Key(免费版好像是最多只有 2 active browsers 一起工作,单月 1000 个 credit,不过对我来说也够了),填到 Dify 的 Firecrawl 插件配置中:
然后就可以去爬网站了。
最后,在 Studio 菜单里创建一个 Chatbot 或 Agent,在右侧的 “上下文” 中关联这个知识库。
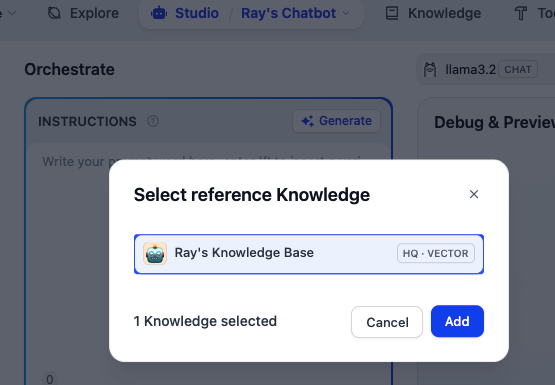
这样,后续问它任何问题,都可以从这个具备个人信息的知识库中进行检索。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》